木を区間で捉えるための Tips
読みやすさを考慮していないので、詳しく知りたい人は最後に載せたリンク先を参照したりしてほしい。
図や表を気休め程度に載せているが、それを手で書いたりしていると理解が深まるかもしれない。
自分はそうしてやっと理解している気になった。
まず木を区間で捉える動機だが、木は更新に弱いが、区間に対応させることで Segment Tree などを用いて比較的容易に扱える。
根付き木における DFS (深さ優先探索) が基本となるが、辿った情報をどのように保存するべきかが重要な点となる。
用途によって少し変わるが、DFS で頂点を訪問順に並べることを考えたとき、大まかに
訪問順に並べた頂点の列
頂点
が最初に出現する場所
頂点
とする。
部分木 (頂点)
各頂点が に
回出現するように頂点を並べる。
このとき、 は葉方向の探索が終了し、根方向に戻るときの
の添え字を表している。
このように情報を保存しておくことで、頂点 以下の部分木は
で取得できる。
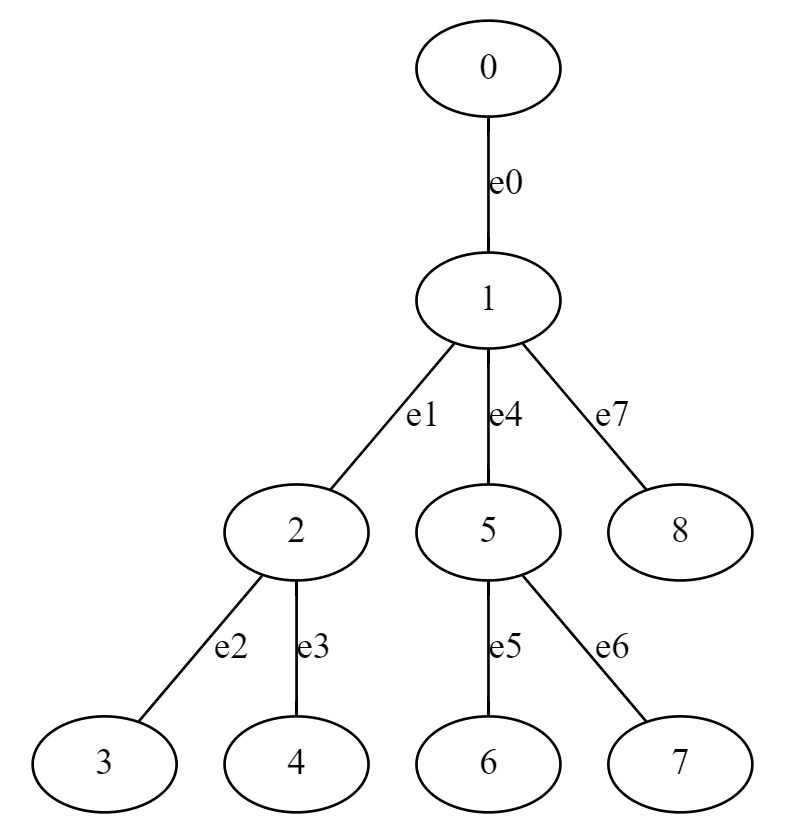
constexpr int MAXV = 200005; vector<int> g[MAXV]; // グラフ (隣接リスト表現) vector<int> vs; // DFS で訪問した順番に頂点を並べたもの int in[MAXV]; // in[v] := v が vs で最初に出現した場所 int out[MAXV]; // out[v] := 根方向に向かう場所 int depth[MAXV]; // 根からの深さ void dfs(int from = 0, int par = -1, int d = 0){ in[from] = vs.size(); vs.emplace_back(from); depth[from] = d; for(int to : g[from]){ if(to != par) dfs(to, from, d + 1); } out[from] = vs.size(); }
以下が一例となる。
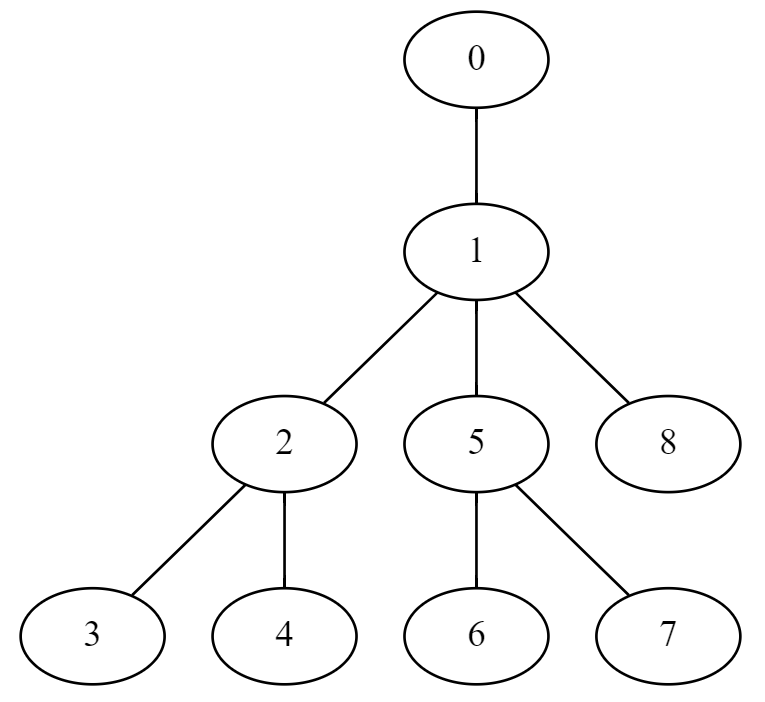

頂点の情報を区間に保存する場合は、 に出現した順にテータを保持しておくとよい。
上の例では が順番に並んでいるが、当然そうとは限らないので注意。
パス (辺)
には、DFS で頂点を訪れるたびに格納していく。
木の頂点数が であるとき、
の長さは
となる。
LCA (最小共通祖先) が必要となるが詳細は省く。
-
間のパスの重みの総和を求めるためには、まず
を求めてから、
-
間と
-
間の問題に分ければよい。
これは例えば -
間では、
の
の総和より求められる。
( LCA でよくある でも求まる。)
一点更新の場合は、 (辺の重みを探索順に並べたもの) をセグ木に入れて、
_
_
を参照して更新できる。
区間更新 (部分木) の場合は、 と
をセグ木に入れて、必要な演算を定義すればよい。
以下のコードでは、用途によっては不必要なデータも保存している。
例えば、 は部分木に対する一様更新のときに用いる。
( 頂点 を根とした部分木は
で取得できる。)
constexpr int MAXV = 200005; struct edge{ int to; int64_t weight; int id; edge(int v, int64_t w, int i) : to(v), weight(w), id(i) {} }; vector<edge> g[MAXV]; // グラフ (隣接リスト表現) vector<int> vs; // DFS で訪問した頂点を並べたもの vector<int64_t> dat; // dat[i] := e=(vs[i],vs[i+1]) の重み (葉方向,根方向)->(+.-) vector<int> sign; // sign[i] := dat[i] の正負 int edge_to_dat[MAXV * 2]; // 辺が dat のどこに保存されているか (id*2+(葉方向:0,根方向:1)) int in[MAXV]; // in[v] := v が vs で最初に出現した場所 int out[MAXV]; // out[v] := 根方向に向かう場所 int depth[MAXV]; // 根からの深さ void dfs(int from = 0, int par = -1, int d = 0){ in[from] = dat.size(); vs.emplace_back(from); depth[from] = d; for(auto [to, weight, id] : g[from]){ if(to == par) continue; // 葉方向 edge_to_dat[id * 2] = dat.size(); dat.emplace_back(weight); sign.emplace_back(1); dfs(to, from, d + 1); // 根方向 vs.emplace_back(from); edge_to_dat[id * 2 + 1] = dat.size(); dat.emplace_back(-weight); sign.emplace_back(-1); } out[from] = dat.size(); }
このコードを例えば以下の木に対して走らせたとき、各データは表のように保存されている。


このようにデータを保持しておくことで、パス上の不要な辺は偶数回出現して打ち消される。
きれいですね。
また、区間一様加算が必要な場合は、例えば以下のように定義してやればできる。
遅延セグ木は、うしさんの抽象化を基にしている。
【URL】https://ei1333.github.io/luzhiled/snippets/structure/segment-tree.html
いつもありがとう...
struct Node { int64_t sum; // 区間総和 int weight; // ('+' の個数) - ('-' の個数) Node(int64_t s = 0, int w = 0) : sum(s), weight(w) {} }; auto op = [](Node a, Node b){ return Node(a.sum + b.sum, a.weight + b.weight); }; auto mapping = [](Node a, int64_t x){ return Node(a.sum + x * a.weight, a.weight); }; auto composition = [](int64_t a, int64_t b){return a + b;}; int N = dat.size(); LazySegmentTree<Node, int64_t> seg(N, op, mapping, composition, Node(), 0);
パス (頂点)
未 verify です。
手軽な確認問題があれば誰か教えてください。
( 2021/02/27 追記 : 更新なしは No.386 貪欲な領主 - yukicoder で verify できました。)
-
間のパス上の頂点の重みの総和は、辺のときと異なり、
と閉区間であることに注意する。
加えて、 の重みは余分に足されるので、
回減算する必要がある。
頂点 に対する一点更新の場合は、根方向が
、葉方向が
に保存されているので、そこを更新すればよい。
頂点 を根とした部分木は
で取り出せる。( ここも閉区間であることに注意! )
constexpr int MAXV = 200005; vector<int> g[MAXV]; // グラフ (隣接リスト表現) int64_t weight[MAXV]; // 頂点の重み vector<int> vs; // DFS で訪問した頂点を並べたもの vector<int64_t> dat; // dat[i] := vs[i] の重み (葉方向,根方向)->(+.-) vector<int> sign; // sign[i] := dat[i] の正負 int in[MAXV]; // in[v] := v が vs で最初に出現した場所 int out[MAXV]; // out[v] := 根方向に向かう場所 int depth[MAXV]; // 根からの深さ void dfs(int from = 0, int par = -1, int d = 0){ // 葉方向 in[from] = vs.size(); vs.emplace_back(from); dat.emplace_back(weight[from]); sign.emplace_back(1); depth[from] = d; for(int to : g[from]){ if(to != par) dfs(to, from, d + 1); } // 根方向 out[from] = vs.size(); vs.emplace_back(from); dat.emplace_back(-weight[from]); sign.emplace_back(-1); }
パス (辺) と同じように以下の木に対して走らせると、データは表のように保存される。



また、例によってうしさんのセグ木を用いると、 -
間のパスは以下のように書いて求めることができる。
// [ in[lca], in[u] ] + [ in[lca], in[v] ] - dat[in[lca]] seg.query(in[lca], in[u] + 1) + seg.query(in[lca], in[v] + 1) - dat[in[lca]];
参考文献
Mo's algorithm - ei1333の日記
Euler Tour のお勉強 | maspyのHP
雑記
下書きに突っ込んだまま放置してたら ABC187 で必要になったけど、コードすら書いてなくてどうして...となった。
また、図や表を python に作らせていたが、慣れてなくて大変なことになった。
知らない間に年が明けていて困った。