多角形と点の内外判定
理解するのに少し時間がかかったので、次回以降に考えなくて済むようにメモ。
なので中身はあまりない。
ある点 p が多角形 polygon (凸とは限らない) の中にあるかどうかを判定。
Crossing Number Algorithm を使う。(下記 reference 参照)
ほぼパクリだが下の実装例では、点 p から左に半直線を伸ばしたときに、多角形の辺といくつ交点を持つかを調べている。
(交点の個数の偶奇だけが問題なので、衝突が検出されるたびに boolean 変数を反転している。)
交点を持つとき、どのような位置関係になるかを見てみる。
点 p を通る半直線の下側に点 a が、上側に点 b があるときを考える。
半直線と線分 ab が交点を持つかどうかは、下図のように点 p と点 a を通る直線の下側に点 b があるかで判定できる。
これは、外積を用いた正負判定で簡単に書ける。

また、 の部分は浮動小数点数
が与えられたとき、
を満たす
を
にみなすということである。(多分)
実装例
using ld = long double; using Point = complex<ld>; using Polygon = vector<Point>; constexpr ld eps = 1e-9; // 外積 ld cross(const Point& a, const Point& b){ return a.real() * b.imag() - a.imag() * b.real(); } // 内積 ld dot(const Point& a, const Point& b){ return a.real() * b.real() + a.imag() * b.imag(); } // CCW : Counter-ClockWise enum class CCW_RESULT{ CCW = +1, CW = -1, BEHIND = +2, FRONT = -2, ON = 0 }; // a, b を通る直線に対して、c がどの位置にあるか CCW_RESULT ccw_enum(Point a, Point b, Point c){ b -= a, c -= a; if(cross(b, c) > eps) return CCW_RESULT::CCW; // 上側 if(cross(b, c) < -eps) return CCW_RESULT::CW; // 下側 // cross(b, c) == 0 if(dot(b, c) < 0) return CCW_RESULT::BEHIND; // 同一直線上の左側 if(norm(b) < norm(c)) return CCW_RESULT::FRONT; // 同一直線上の右側 return CCW_RESULT::ON; // 線分 ab 上にある } int ccw(Point a, Point b, Point c){ return static_cast<int>(ccw_enum(a, b, c)); } enum class CONTAIN_RESULT { OUT = 0, ON = 1, IN = 2 }; // polygon の隣り合う頂点は辺をなす // つまり、線分 polygon[i] - polygon[i+1] が辺である CONTAIN_RESULT contain_point_enum(const Polygon& polygon, const Point& p){ int n = polygon.size(); // 点 p が多角形 polygon の辺上にあるか for(int i = 0; i < n; ++i){ int place = ccw(polygon[i], polygon[(i + 1) % n], p); if(place == static_cast<int>(CCW_RESULT::ON)){ return CONTAIN_RESULT::ON; } } // Crossing Number Algorithm bool in = false; for(int i = 0; i < n; ++i){ Point a = polygon[i] - p; Point b = polygon[(i + 1) % n] - p; if(a.imag() > b.imag()) swap(a, b); if(a.imag() < eps && eps < b.imag() && cross(a, b) < -eps){ in = !in; } } return in ? CONTAIN_RESULT::IN : CONTAIN_RESULT::OUT; } int contain_point(const Polygon& polygon, const Point& p){ return static_cast<int>(contain_point_enum(polygon, p)); }
reference
幾何テンプレート(Geometry) | Luzhiled’s memo
実装をパクり参考にした。
雑記
一体何してる?
今後 GitHub に上げるかもしれないし、上げないかもしれない。
ABC267 G - Increasing K Times の計算量について
解説見ても計算量について理解できなかったので、自分なりに考えたものの備忘録。
問題
長さ の整数列
が与えられる。
これを並び替えた数列を として、次の条件を満たすものの総数を
で割った余りを求める。ただし、重複する要素は区別する。
・ となる
の個数がちょうど
個である。
制約
計算量
DP を次のように定義して、 の要素昇順で並べ方を決める。
個並べているときの、
となる
の個数がちょうど
個である並べ方
まず、 の要素がすべて異なる distinct である状態を考える。
このとき、DP テーブルの各マスからの遷移は高々 通りであり、計算量は
となる。( 下図参照 )

次に、重複する要素が存在する場合を考える。
distinct であるときの遷移からどう変化するのかを考えてみる。
個並べた数列に新しく追加する要素が
個から
個に増えたとする。
( 一例を下に示す。)

distinct では 行目から
行目への遷移だったものが、
行目から
行目への遷移となる。
このとき、distinct であるときの 行目から
行目への遷移に必要な計算 (最大
回) がなくなり、
行目からの遷移は各マスについて高々
回増える。
ゆえに、重複する要素が発生しても、distinct であるときと比べて計算回数は増えない。
重複が 個以上になっても、
個ずつ重複する要素が増えると考えて、おそらく同じことが言える。
よって、DP の更新の計算量は となる。
雑記
遷移の条件を間違えてドヤ顔で遷移を畳込みにしたら、サンプルすら合わなくて虚無になっていた。
コンテスト中だとナイーブでも計算量大丈夫やろで、無証明提出しそう。
そもそもこの問題を解く人はこんなところで躓かんよな......
最近コンテスト全然解けないので、時間内にここまでいくことがなくて悲しい。
この記事、一ヶ月以上前に書いたまま放置していて震えあがった。
体調崩してた記憶しかねえ......
ここ数日は、珍しくライブラリ整備していた。
永続データ構造と HL 分解を書いてたけど、使うときがくる気がしない。
ところで社会復帰はいつ?
複素平面上の回転移動
いつも忘れるのでメモ。
複素平面上の回転は複素数の積で表せる。
回転させたいとき、回転させたい座標に偏角
の単位ベクトルをかければよい。
C++ だと complex クラスを使えば簡単に記述できる。
( 極形式 の複素数表記は polar で取得できる。)
複素平面を勉強したことがないので、回転行列使えばいいかという気もする。
コード
template<typename T> complex<T> rotate_radian(complex<T> z, T radian){ return z * polar(1.0, radian); } template<typename T> complex<T> rotate_degree(complex<T> z, T degree){ // 1 degree = pi / 180.0 return z * polar(1.0, degree * acos(-1) / 180.0); }
雑記
生きてる価値がない上に、水色に落ちて虚無が加速した。
どうしてこうなった。
雑記部分は多分いずれ消す。
包除原理に関するメモ
余事象を考えて包除原理を用いる問題に出会う度、理解に時間がかかるのでメモ。
「すべて~ない」などの条件をもった場合の数を直接求めるのは難しく、否定の条件を考えて余事象で求めることがある。
例えば、求める条件が任意の に対して
であるというときに
という条件を考える、など。
否定の条件を禁止事項と呼ぶことにする。
E - NEQ や F - Heights and Pairs のように、禁止事項の個数で状態がまとめられるとき、少なくとも 個禁止事項を持つ集合を
(要素数 :
) とする。
に関して重要なのは、禁止事項以外は自由に決められるので
個より多く禁止事項を持つ可能性がある。(このおかげで数えやすい。)
また、全事象は禁止事項 個以上とも取れるので
である。
求める場合の数は全事象から禁止事項を持つ場合の数を引いたものであるので、禁止事項の個数の上限を とすると、
(∵包除原理)
と表せる。
アルゴリズムの簡単なまとめ Wiki - yukicoder にあるように、
と捉えるのは簡潔ですごい。
ただ、自分は まわりをどう捉えればいいか分からなくなってしまったので、ひとまず前述の形で理解することにした。
全方位木 DP の抽象化
全方位木 DP の抽象化を書いてみた。
コードと使用例のみ。(使用例はネタバレあり)
気が向いたら解説を書くかもしれない、未来の自分に期待。
少しだけ書くと、rerooting_function では、子ノードの subtree_dp の累積を両側から取って、それぞれの子ノードに対して rerooting_dp を求めるということをしている。
( 2021/02/16 修正 : E - 限界集落 のように辺に向きがある場合に困ったので、子ノードに根方向の部分木の情報を伝播させて、ノードに訪れたときに rerooting_dp を更新するように変更。また、重み付きの方に有向辺を入れる関数も追加。)
最後の参考文献に上げたリンク先を参照すると分かりやすいかもしれない。
このような実装が不必要な場合もあるが、使用例の問題のように割り算ができない場合にも対応するためにもこの実装にした。
あまり多くの問題を見てないので、抽象化がこれでいいのか分からない。
適宜訂正していく可能性が大いにある。
※頂点重み付きも追加 (2021/04/04)
使用例 (ネタバレ注意)
重み付き
http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=1595
木の直径を求める。
2 回 DFS すればできるが、全方位木 DP でやってみる。
雑記
全方位木 DP しばらく書かずにいるとバグらせがちなので、ライブラリにしてみた。
ただ、ライブラリを書き上げてから、もっと他にやるべきことがあるだろ?暇人かよ、という気持ちになり悲しくなった。
こういうのは GitHub に上げるのがいいのだろうか。
コードを見れば分かるのだが、効率の悪いことをしている。
自分は高速化にそこまで興味がないので放置してしまっているが、直してくれる誰かに期待......
木を区間で捉えるための Tips
読みやすさを考慮していないので、詳しく知りたい人は最後に載せたリンク先を参照したりしてほしい。
図や表を気休め程度に載せているが、それを手で書いたりしていると理解が深まるかもしれない。
自分はそうしてやっと理解している気になった。
まず木を区間で捉える動機だが、木は更新に弱いが、区間に対応させることで Segment Tree などを用いて比較的容易に扱える。
根付き木における DFS (深さ優先探索) が基本となるが、辿った情報をどのように保存するべきかが重要な点となる。
用途によって少し変わるが、DFS で頂点を訪問順に並べることを考えたとき、大まかに
訪問順に並べた頂点の列
頂点
が最初に出現する場所
頂点
とする。
部分木 (頂点)
各頂点が に
回出現するように頂点を並べる。
このとき、 は葉方向の探索が終了し、根方向に戻るときの
の添え字を表している。
このように情報を保存しておくことで、頂点 以下の部分木は
で取得できる。
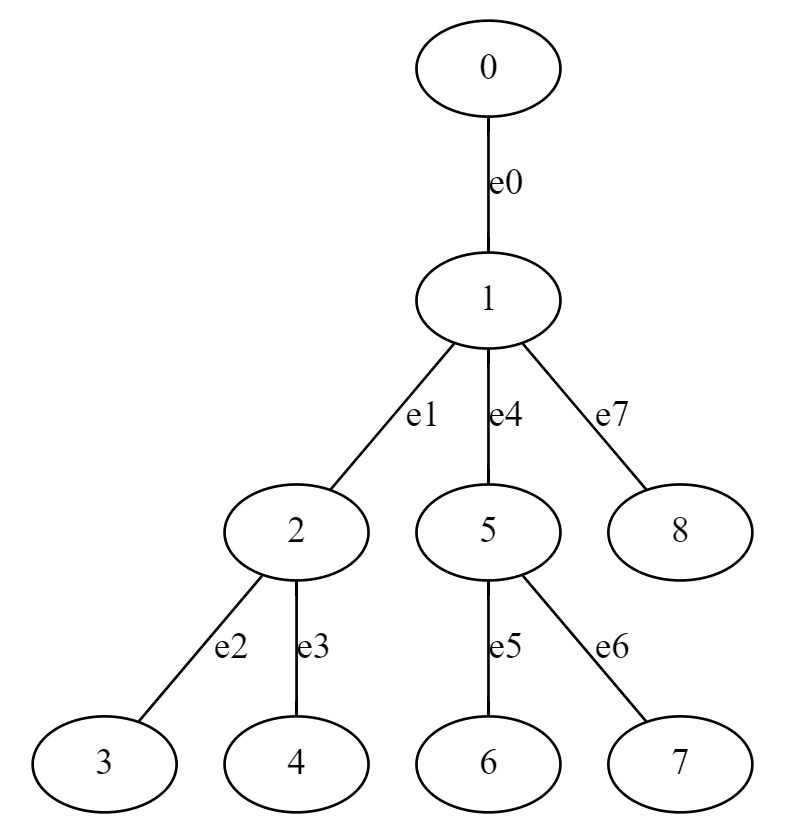
constexpr int MAXV = 200005; vector<int> g[MAXV]; // グラフ (隣接リスト表現) vector<int> vs; // DFS で訪問した順番に頂点を並べたもの int in[MAXV]; // in[v] := v が vs で最初に出現した場所 int out[MAXV]; // out[v] := 根方向に向かう場所 int depth[MAXV]; // 根からの深さ void dfs(int from = 0, int par = -1, int d = 0){ in[from] = vs.size(); vs.emplace_back(from); depth[from] = d; for(int to : g[from]){ if(to != par) dfs(to, from, d + 1); } out[from] = vs.size(); }
以下が一例となる。
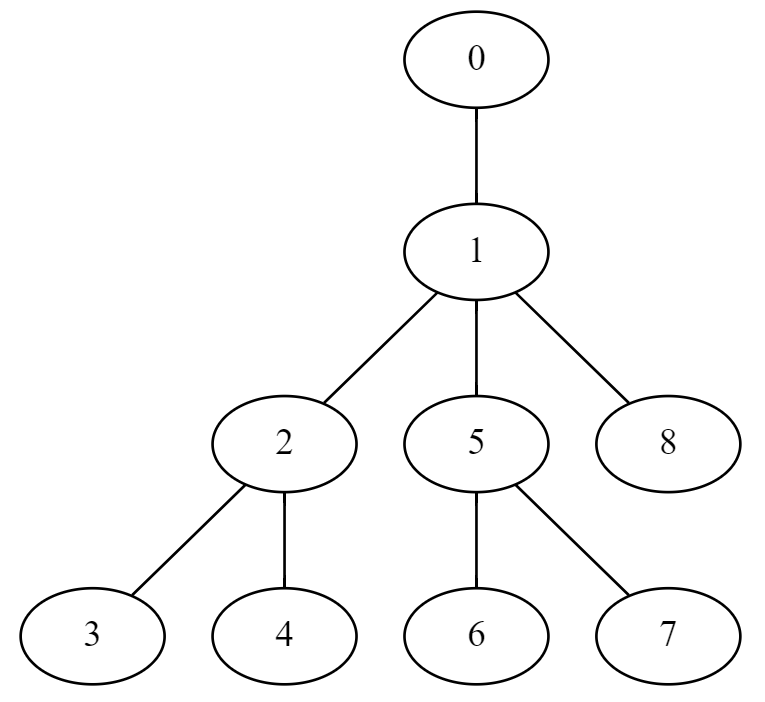

頂点の情報を区間に保存する場合は、 に出現した順にテータを保持しておくとよい。
上の例では が順番に並んでいるが、当然そうとは限らないので注意。
パス (辺)
には、DFS で頂点を訪れるたびに格納していく。
木の頂点数が であるとき、
の長さは
となる。
LCA (最小共通祖先) が必要となるが詳細は省く。
-
間のパスの重みの総和を求めるためには、まず
を求めてから、
-
間と
-
間の問題に分ければよい。
これは例えば -
間では、
の
の総和より求められる。
( LCA でよくある でも求まる。)
一点更新の場合は、 (辺の重みを探索順に並べたもの) をセグ木に入れて、
_
_
を参照して更新できる。
区間更新 (部分木) の場合は、 と
をセグ木に入れて、必要な演算を定義すればよい。
以下のコードでは、用途によっては不必要なデータも保存している。
例えば、 は部分木に対する一様更新のときに用いる。
( 頂点 を根とした部分木は
で取得できる。)
constexpr int MAXV = 200005; struct edge{ int to; int64_t weight; int id; edge(int v, int64_t w, int i) : to(v), weight(w), id(i) {} }; vector<edge> g[MAXV]; // グラフ (隣接リスト表現) vector<int> vs; // DFS で訪問した頂点を並べたもの vector<int64_t> dat; // dat[i] := e=(vs[i],vs[i+1]) の重み (葉方向,根方向)->(+.-) vector<int> sign; // sign[i] := dat[i] の正負 int edge_to_dat[MAXV * 2]; // 辺が dat のどこに保存されているか (id*2+(葉方向:0,根方向:1)) int in[MAXV]; // in[v] := v が vs で最初に出現した場所 int out[MAXV]; // out[v] := 根方向に向かう場所 int depth[MAXV]; // 根からの深さ void dfs(int from = 0, int par = -1, int d = 0){ in[from] = dat.size(); vs.emplace_back(from); depth[from] = d; for(auto [to, weight, id] : g[from]){ if(to == par) continue; // 葉方向 edge_to_dat[id * 2] = dat.size(); dat.emplace_back(weight); sign.emplace_back(1); dfs(to, from, d + 1); // 根方向 vs.emplace_back(from); edge_to_dat[id * 2 + 1] = dat.size(); dat.emplace_back(-weight); sign.emplace_back(-1); } out[from] = dat.size(); }
このコードを例えば以下の木に対して走らせたとき、各データは表のように保存されている。


このようにデータを保持しておくことで、パス上の不要な辺は偶数回出現して打ち消される。
きれいですね。
また、区間一様加算が必要な場合は、例えば以下のように定義してやればできる。
遅延セグ木は、うしさんの抽象化を基にしている。
【URL】https://ei1333.github.io/luzhiled/snippets/structure/segment-tree.html
いつもありがとう...
struct Node { int64_t sum; // 区間総和 int weight; // ('+' の個数) - ('-' の個数) Node(int64_t s = 0, int w = 0) : sum(s), weight(w) {} }; auto op = [](Node a, Node b){ return Node(a.sum + b.sum, a.weight + b.weight); }; auto mapping = [](Node a, int64_t x){ return Node(a.sum + x * a.weight, a.weight); }; auto composition = [](int64_t a, int64_t b){return a + b;}; int N = dat.size(); LazySegmentTree<Node, int64_t> seg(N, op, mapping, composition, Node(), 0);
パス (頂点)
未 verify です。
手軽な確認問題があれば誰か教えてください。
( 2021/02/27 追記 : 更新なしは No.386 貪欲な領主 - yukicoder で verify できました。)
-
間のパス上の頂点の重みの総和は、辺のときと異なり、
と閉区間であることに注意する。
加えて、 の重みは余分に足されるので、
回減算する必要がある。
頂点 に対する一点更新の場合は、根方向が
、葉方向が
に保存されているので、そこを更新すればよい。
頂点 を根とした部分木は
で取り出せる。( ここも閉区間であることに注意! )
constexpr int MAXV = 200005; vector<int> g[MAXV]; // グラフ (隣接リスト表現) int64_t weight[MAXV]; // 頂点の重み vector<int> vs; // DFS で訪問した頂点を並べたもの vector<int64_t> dat; // dat[i] := vs[i] の重み (葉方向,根方向)->(+.-) vector<int> sign; // sign[i] := dat[i] の正負 int in[MAXV]; // in[v] := v が vs で最初に出現した場所 int out[MAXV]; // out[v] := 根方向に向かう場所 int depth[MAXV]; // 根からの深さ void dfs(int from = 0, int par = -1, int d = 0){ // 葉方向 in[from] = vs.size(); vs.emplace_back(from); dat.emplace_back(weight[from]); sign.emplace_back(1); depth[from] = d; for(int to : g[from]){ if(to != par) dfs(to, from, d + 1); } // 根方向 out[from] = vs.size(); vs.emplace_back(from); dat.emplace_back(-weight[from]); sign.emplace_back(-1); }
パス (辺) と同じように以下の木に対して走らせると、データは表のように保存される。



また、例によってうしさんのセグ木を用いると、 -
間のパスは以下のように書いて求めることができる。
// [ in[lca], in[u] ] + [ in[lca], in[v] ] - dat[in[lca]] seg.query(in[lca], in[u] + 1) + seg.query(in[lca], in[v] + 1) - dat[in[lca]];
参考文献
Mo's algorithm - ei1333の日記
Euler Tour のお勉強 | maspyのHP
雑記
下書きに突っ込んだまま放置してたら ABC187 で必要になったけど、コードすら書いてなくてどうして...となった。
また、図や表を python に作らせていたが、慣れてなくて大変なことになった。
知らない間に年が明けていて困った。
Educational Codeforces Round 101 - E. A Bit Similar
酒入ってたけど、入ってなくても思いつかなかったな。
問題概要
つの
文字列で
文字でも一致する状態を "a bit similar" であるとする。
文字列 が与えられたとき、
から得られる長さ
の部分文字列すべてに対して "a bit similar" である辞書順最小の
文字の文字列を求める。(なければ "NO" と答える。)
テストケースは 個与えられる。
補足 : 部分文字列は、文字列の連続する部分列のことである。
制約
解法
と
を反転した文字列を考える。
この文字列に現れる長さ の部分文字列は、題意を満たさないと言える。
例えば、"0110" を反転させた "1001" を見てみる。( とする。)
文字ずつスライドしてみていくと、
0110
1001
0110
1001
0110
1001
となっていて、反転前の部分文字列を見ると "a bit similar" でないので、確かに題意を満たさない。
ただ、 文字列を考えているので、それぞれ
文字でも異なっていれば、"a bit similar" でなかったものは "a bit similar" となる。
このことから、反転させた文字列から取れる部分文字列に含まれていない長さ の文字列は、題意を満たす。
したがって、出現した部分文字列を管理して、出現しなかった辞書順最小のものを答えとすればよい。(すべて出現していれば "NO" となる。)
( 進表記で見ると、mex (集合に含まれない最小の数) を
の範囲内で求めることと同じ。)
ただ、そのまま実装にうつると、部分文字列の列挙に かかって大変なことになるので、もう一工夫する必要がある。
部分文字列の個数は 個あるが、この個数は制約から
で抑えられる。
よって、 の場合は先頭
文字を
で埋めても問題はない。(自由度を下位
桁に制限しても、
通りあるので、必ず解が存在して "YES" となる。)
考慮すべきなのは、先頭 文字が
である部分文字列の下位
文字であり、これを集合に追加すればよい。(先頭に
が含まれていれば、その時点で求めようとしている文字列と反転前の部分文字列とは "a bit similar" になるので、考慮する必要はない。)
コード
#include <iostream> #include <string> #include <set> #include <vector> using namespace std; void solve(){ int n, k; string s; cin >> n >> k >> s; // '0' '1' 反転 for(int i = 0; i < n; ++i) s[i] = s[i] == '0' ? '1' : '0'; // 出現した部分文字列を 2 進数として集合で管理 set<int> st; if(k <= 20){ for(int i = 0; i + k <= n; ++i){ st.emplace(stoi(s.substr(i, k), nullptr, 2)); } } else{ vector<int> zeros(n + 1); for(int i = 0; i < n; ++i){ zeros[i + 1] = zeros[i] + (s[i] == '0'); } for(int i = 0; i + k <= n; ++i){ // 先頭 (k - 20) 文字が 0 で埋まっていれば、集合に要素を追加 if(zeros[i + k - 20] - zeros[i] == k - 20){ st.emplace(stoi(s.substr(i + k - 20, 20), nullptr, 2)); } } } // mex を求める int ans = -1; for(int num = 0; num < 1 << min(k, 20); ++num){ // num が集合になければ ans を保存してループを抜ける if(st.find(num) == st.end()){ ans = num; break; } } if(ans == -1) cout << "NO\n"; else{ cout << "YES\n"; for(int i = 0; i < k - 20; ++i) cout << 0; for(int i = min(k, 20) - 1; i >= 0; --i) cout << (ans >> i & 1); cout << '\n'; } } int main(){ int q; cin >> q; while(q--) solve(); return 0; }
雑記
コンテスト後に解法ツイートを眺めていたが、どうしてビット列を反転させているのかしばらく分からなかった。
難しい。